Research
Can Cyber-Capable models fix AppSec?
A technical analysis of why modern AppSec continues to miss critical vulnerabilities despite an abundance of tools and where upcoming cyber-capable models can help.
May 12, 2026
Guy Eisenkot
A technical analysis of why modern AppSec continues to miss critical vulnerabilities despite an abundance of tools and where upcoming cyber-capable models can help.
For a long time, AppSec has had a strange shape in the DevTool landscape. We have tools that were very good at looking at code, packages, repositories, APIs, containers, secrets, cloud resources, and even runtime. We built markets around each of these: SAST, DAST, SCA, SBOMs, IaC scanning, API security, CNAPP, ASPM, WAFs, code review, bug bounty, secret scanning, and more. Some consolidated into platforms over time, while others continued to provide value finding possible risk in growing codebases.

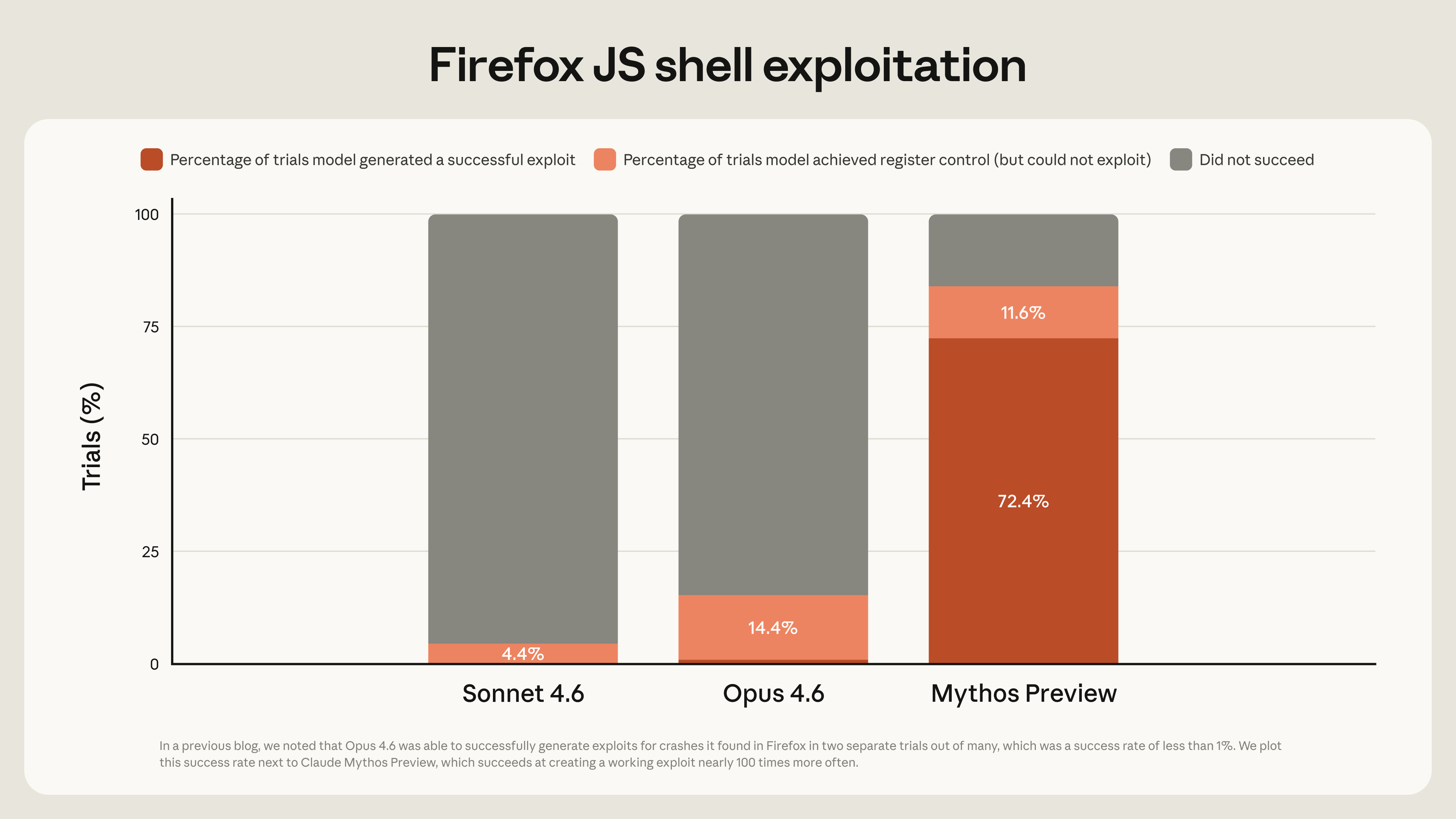
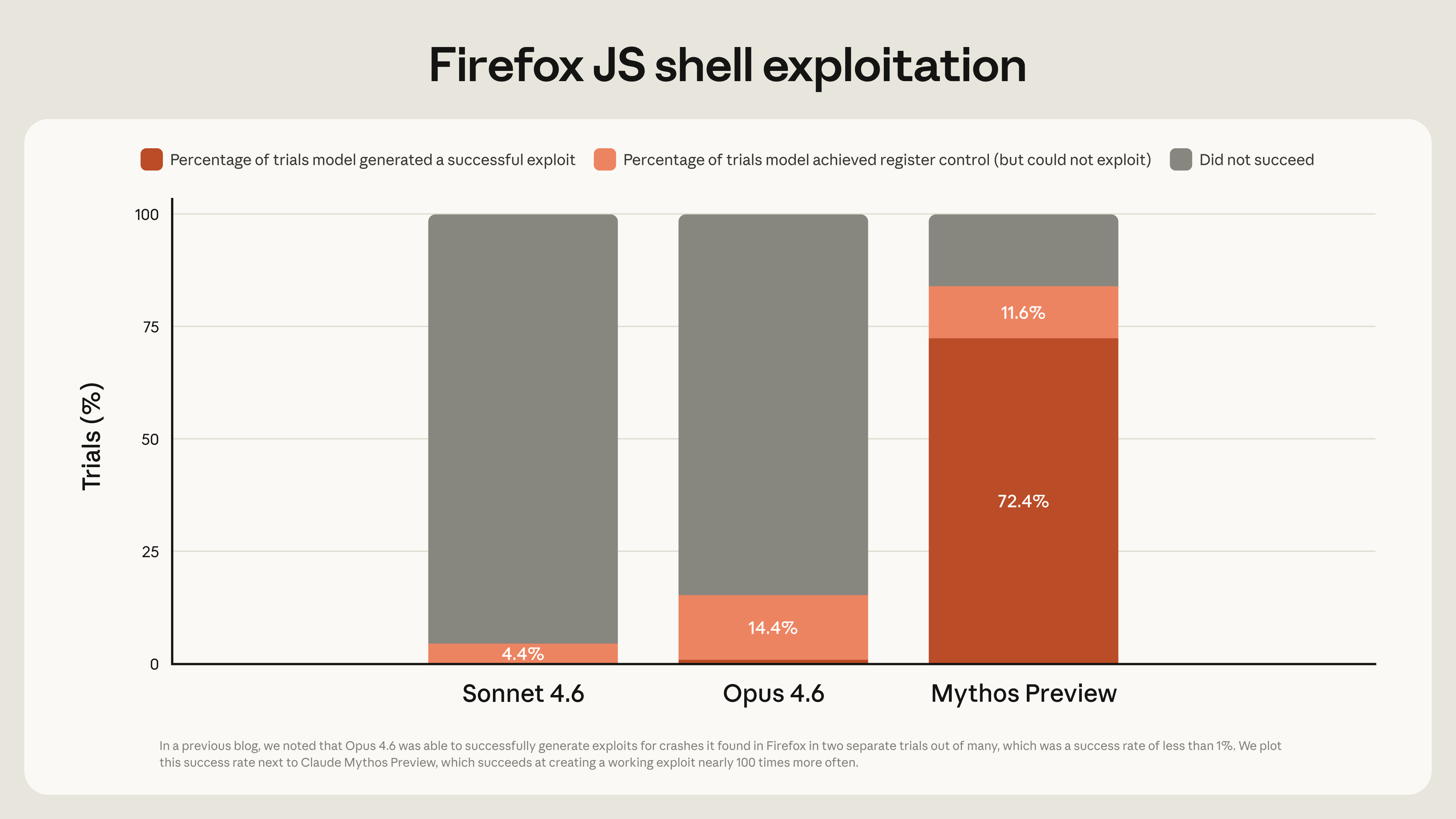
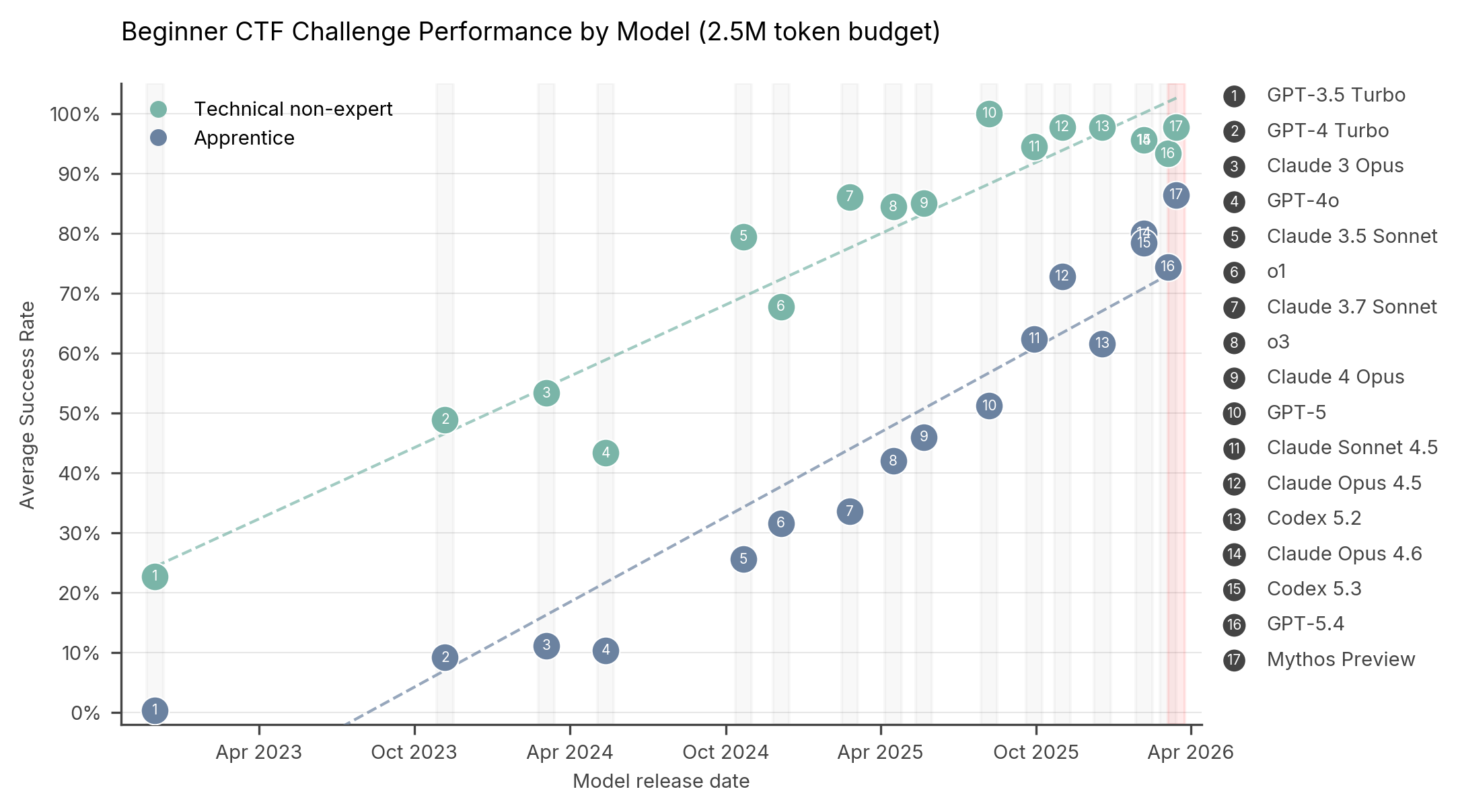
Cyber-capable models like Claude Mythos Preview and GPT-Cyber-class systems are interesting because they might be the first practical way to make security context cheap enough to apply continuously. Anthropic says Claude Mythos Preview has identified thousands of zero-day vulnerabilities across major operating systems, browsers, and other important software, while OpenAI’s Trusted Access for Cyber program is explicitly designed to give verified defenders access to more cyber-capable models, including GPT‑5.4‑Cyber, for advanced defensive workflows such as vulnerability research and binary reverse engineering.
Most AppSec tools start from an inventory: Source code repositories. Dependency manifests. Container images. Terraform modules. SBOMs. Pull requests. API schemas. Runtime traces etc... This seems natural since artifacts are inspectable and in most engineering orgs they have owners and they can be changed in a well defined workflow.
Attackers operate very similarly with one big exception - they rarely stop at the artifact boundary. They move from code to cloud identity, from cloud identity to runtime, from runtime to internal network, from internal network to registry, from registry to CI/CD, from CI/CD to trusted release.
Can we make models reason over that whole path? A synchronous agent could sit in a design review (BEFORE ANY CODE HAS BEEN WRITTEN) and ask: what credentials are reachable from this notebook runtime? What internal services does it call? What tenant identity is attached to those calls? Is there any shared key material? Does the runtime have metadata access? Where are the customer keys decrypted An asynchronous agent could keep checking the same property. Every new service mesh rule, IAM change, notebook image, network policy, and backend deployment could be compared against the invariant: tenant code must not reach provider-wide trust.
The problem with scanners is never detection logic, it's mostly context and scope. If we treat the agent like a scanner don't be surprised if we just get the same inventory we already have.
A lot of textbook DAST and quite frankly threat modeling assumes the attacker begins outside the system and this made sense for a web-first world. DAST, WAF, WAAP, API gateways, and external attack-surface management all came from a new internet-facing mental model. What can the unauthenticated or low-privilege outsider reach?
SaaS and AI platforms need a harsher assumption. Supply chain compromises up and down the stack mean bad actors may already be allowed to create a repository, submit a model, run a notebook, start a training job, or run database functions.
The Kubernetes ingress-nginx vulnerabilities are a useful example. The Kubernetes Security Response Committee said CVE‑2025‑1974 allowed anything on the pod network to exploit configuration-injection vulnerabilities through the validating admission controller. Because ingress-nginx commonly had access to cluster-wide Secrets, this could lead to cluster takeover. In other words, Kubernetes, the leading runtime platform for almost everything, had a reachability problem.

A cyber-capable model can help because this is a multi-hop question. It requires reading service-specific objects and threat modeling as if only one of them was compromised.
Think about it this way - what if you can manage an agent with adversarial mindset to evaluate the posture of RBAC, service accounts, network policy, controller versions, admission webhook configuration, and deployment topology. A synchronous version helps while the platform team is changing the cluster. An asynchronous version watches for drift. The model should not merely say “there is a Kubernetes risk.” It should say “an untrusted pod can reach a privileged admission component that can expose cluster secrets.”
SCA and vulnerability management are strongest after disclosure and they are still incredibly valuable because fast patching matters. The way this worked in recent years was that at the bottom of the pyramid hundreds of versions are compromised across historic versions spread across artifact distribution platforms. Emergency patching consumed Christmas Eve for practically every AppSec practitioner in recent years.
SCA, SBOM, and vulnerability management work well after disclosure. Attackers will find more and more unknown flaws, design bugs, or dangerous chains where no single CVE represents the full risk.
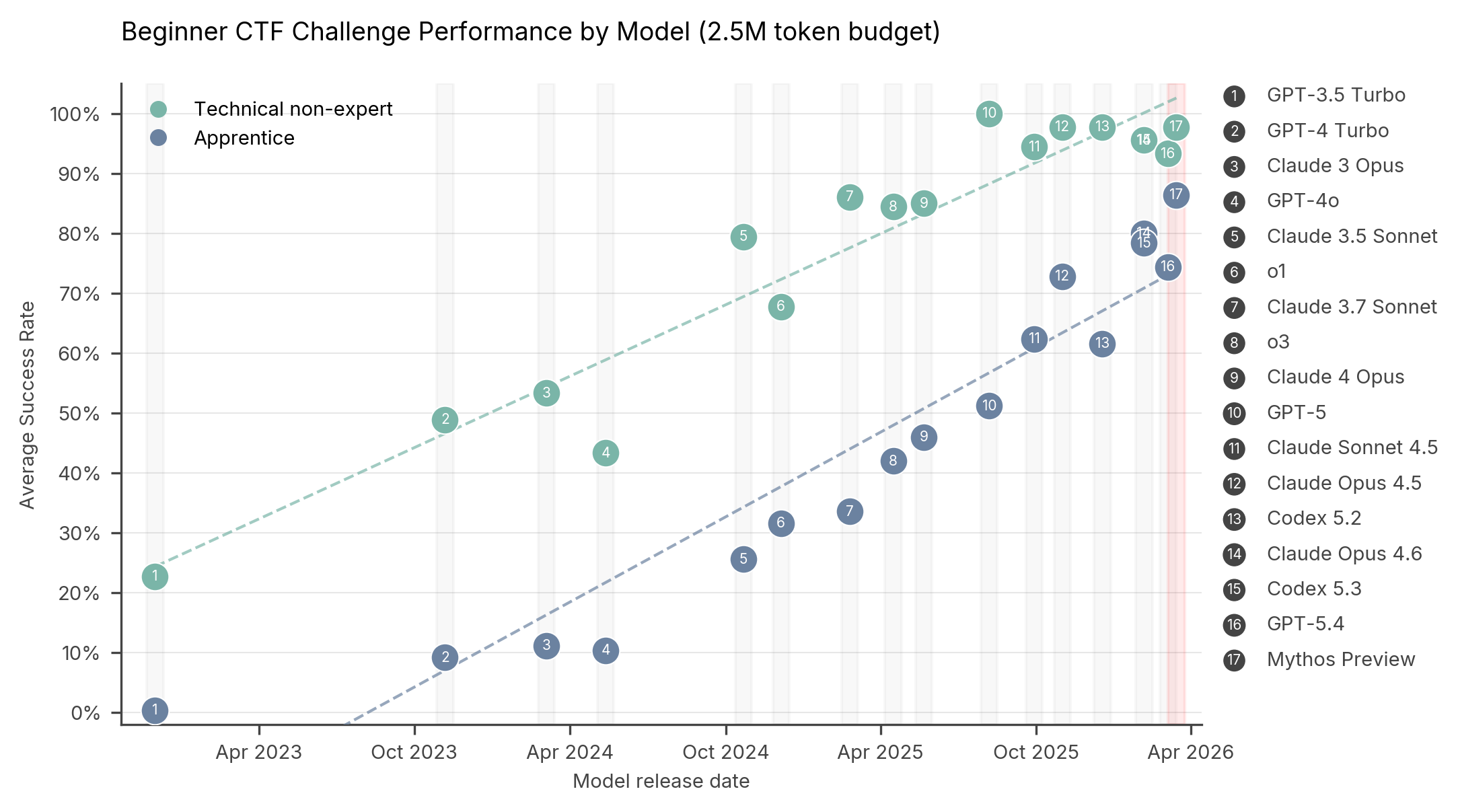
We're seeing early signs we can start to instruct agents to reason about dangerous capabilities before the CVE.
A model with enough context could ask whether scripting is enabled, which identities can invoke it, whether a DB is reachable from untrusted workloads, whether dangerous commands are restricted, whether the process runs as root, whether it can reach cloud metadata, and whether egress is allowed. The same applies to self-hosted developer services.
Traditional AppSec treats the application as the thing to secure. The thing to secure is the platform that produces and runs the application. That includes CI/CD, Kubernetes, cloud identities, service meshes, registries, admission controllers, model runners, notebook runtimes, storage backends, databases, GPU runtimes, internal APIs, and tenant boundaries.
This matters especially for AI infrastructure. AI products invite users to bring models, containers, notebooks, and training jobs. Many of those workloads need GPUs. If a platform treats a container as a sufficient tenant boundary, the security model is already too optimistic.
A synchronous agent should be able to challenge this in architecture review, while an asynchronous model can keep a live map.
The last problem is the most familiar, AppSec finds things, engineering fixes some of them, and the backlog remembers.
This is partly because scanners produce too much noise. But it is also because findings are usually ranked as isolated objects: A medium secret, a medium network path, a medium CI permission, and a medium registry issue may be a critical supply-chain path when combined.
This is where synchronous and asynchronous modes complement each other... In synchronous mode, the agent helps during triage. It turns a loose set of alerts into a concrete remediation argument. “Patch this first because it is reachable from untrusted workloads and leads to cluster secrets.” “Rotate this credential because it is present in a runtime namespace that tenant jobs can reach.” “Do not merge this CI change because it gives untrusted pull requests access to a token that can publish artifacts.” In asynchronous mode, the agent verifies. It checks whether the patch was deployed, whether the vulnerable service restarted, whether the network path was removed, whether the token was rotated, whether the registry permission became pull-only, and whether the regression test now fails safely.
The easiest place to imagine these models is inside the moment of code composition/generation and obviously code review.The harder and more interesting version happens in the background.
Many AppSec tasks are too slow for the foreground.
OpenAI says frontier cyber models have moved from editor completion toward working autonomously for hours or days on complex tasks, and its Trusted Access program is explicitly structured around the ambiguity of powerful dual-use cybersecurity work.
The future AppSec programs are probably not daily codebase scans that wait for a human to triage.
The first promising direction is invariant-driven AppSec instructions. Instead of starting with tool categories, teams define properties the system must preserve. Tenant code cannot reach provider credentials. Untrusted builds cannot receive release secrets. Runtime workloads cannot write trusted artifacts. Model containers cannot reach host resources. Internal APIs cannot trust network location alone. The model’s job is to test these properties across code, cloud, and runtime.
The second is live context. The best teams will not retrieve only source code. They will retrieve architecture docs, CI histories, cloud IAM, Kubernetes manifests, runtime telemetry, package provenance, registry state, service ownership, incident history, and finally production exposure.
The third is safe hostile-tenant simulation. SaaS and AI platforms need controlled tenants designed for security testing. They should contain fake data, canary credentials, and realistic workflows. Cyber-capable models can then exercise internal reachability without touching real customers.
The fourth is model-assisted patch proof. It is not enough to suggest a fix. The model should generate the regression test, identify the deployment path, check the runtime state, and confirm that the dangerous chain is broken.
The fifth is governance for dual-use capability. Powerful cyber models should run with verified access, isolated execution, bounded tools, human approval for high-risk actions, and complete audit trails. Otherwise, they become another unmanaged security surface.
**
AppSec does not need another category that promises to replace the previous ones.
SAST will still matter. SCA will still matter. SBOMs, secret scanning, DAST, API security, IaC scanning, CNAPP, ASPM, runtime telemetry, and manual review will still matter.
The reason cyber-capable models are interesting is that they can potentially hold more of the context in mind.
The next AppSec problem is not finding more issues.


.png)
.png)
{kind=link}
{kind=link}